
Contents in the post based on the free Coursera Machine Learning course, taught by Andrew Ng.
Previously, In the case of Linear regression, we learned about Gradient descent and Normal equation. For logistic regression, We would learn Gradient descent and Advanced optimization methods.
This time, We would learn how to adapt Gradient descent and more advanced optimization techniques in regularized logistic regression.
1. Gradient descent algorithm
1.1 Without Regularization
– Cost function of Logistic regression

– Gradient descent
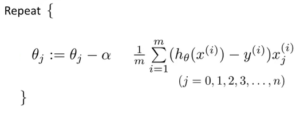
1.2 With Regularization
– Cost function for Logistic regression

– Gradient descent
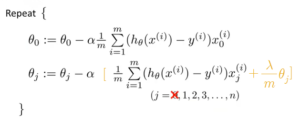
It might look superficially the same with the equation for Regularized Linear regression. But don’t forget that the hypothesis is like below. Therefore it couldn’t be identical.

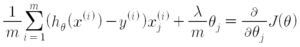
e.g.)



2. Advanced optimization
