
1. Regularized Linear Regression
Previously, We took two learning algorithms (Gradient descent and Normal equation) for Linear regression problems. In this post, We will deal with those two algorithms and generalize them to the case of regularized linear regression.
1.1 Gradient descent without Regularization
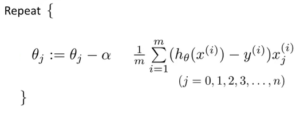
1.2 Gradient Descent for the regularized cost function
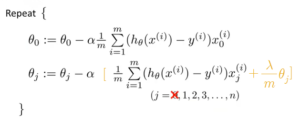
The reason why we do not penalize ![]() is just kind of convention.
is just kind of convention.
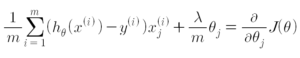
1.2.1 Intuition
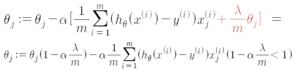
Therefore, By multiplying the value which is a little bit smaller than one, It shrinks the![]() every iteration. And the rear part of the equation is equal to the equation without regularization.
every iteration. And the rear part of the equation is equal to the equation without regularization.
Q. How could we know that is going to be smaller than one?
is going to be smaller than one?
A. will be positive; usually, α is small and m is large
will be positive; usually, α is small and m is large
2. Normal Equation
2.1 Without Regularization
In this case, Θ minimizes the cost function J(Θ) when regularization is not used.
2.2 Regularization
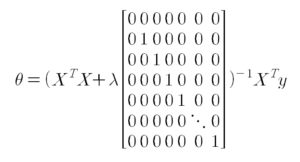
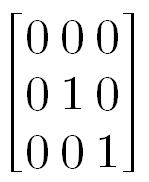
e.g.) n=2
Read More
Contents in the post based on the free Coursera Machine Learning course, taught by Andrew Ng.